接上文:LEETCODE常见算法之深度优先搜索DFS超详细白话讲解(上)
上一篇文章中,我们使用一道二叉树问题讨论了DFS算法在LEETCODE解题时的应用。本文,我们尝试挑战更复杂一点的题目,来看下深度优先搜索是如何解决某些矩阵难题的。
例2:
矩阵中的最长递增路径
给定一个整数矩阵,找出最长递增路径的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
示例:
输入: nums = [ [9,9,4], [6,6,8], [2,1,1] ] 输出: 4
解释: 最长递增路径为[1, 2, 6, 9]。
题目链接:
- 英文: https://leetcode.com/problems/longest-increasing-path-in-a-matrix/
- 中文: https://leetcode-cn.com/problems/longest-increasing-path-in-a-matrix/
- 免费查看题目公司信息: https://leetcode.jp/problemdetail.php?id=329
选择这道矩阵例题的原因是想区别于上篇文章讲过的二叉树问题,解题前,我们有必要讨论一下两道题的区别所在,这对于我们之后做题会有很大的帮助。如果你只是想快速查看本题的实现代码,那么我认为本篇文章并不适合于你,因为我们的初衷是想让大家充分理解DFS算法的应用,能够做到融会贯通,举一反三,这样再遇到类似问题时,能够快速想到使用DFS的解题方案。
本题是一道矩阵题目,其实矩阵也可以看做是多个节点构成的图形结构,矩阵上每一个点可以想象成为一个节点,当前节点能够走到的下一个点都是当前节点的子节点。相比于二叉树,它们之间具有如下区别:
- 题目给出了矩阵上每一点的值,而二叉树问题我们开始只能看到根节点。
- 二叉树在进行DFS递归时,最多只存在2个子节点分叉,而本题,矩阵上的每一点最多可以向四个方向进发,也就是说会出现4个分叉(有些更复杂的题目会出现更多的分叉)。
- 二叉树上的每一个点虽然存在0-2个子节点,但它的上一层父节点只有一个。而在矩阵中的每个点,不仅存在多个子节点,还有可能存在多个父节点(从多个节点到达当前节点)。
- 二叉树的每条路径不存在回路,但矩阵上每个点都可以向四个方向进发,这样一定会出现回路。
除了以上区别之外,本题还有另外一个特殊性,题目中没有给出dfs路径的起点和终点。还记得二叉树的例子吗?它的起点是根节点,终点是层数最大的叶子节点。但对于本题,dfs的起点与终点都有可能是矩阵上的任意一点。这就是本题的复杂之处,不过万变不离其宗,随着你对dfs题目理解的加深,上述问题都不是问题。
其实上面啰嗦了这么多的区别,总结成一句话就是,本题的矩阵问题相比于二叉树问题的路径会变得更多并且更复杂!首先,我们要明白一点,每个点上的分叉数量并不是本题复杂的关键所在!我们来复习一下上篇文章给出的dfs递归函数的模板代码:
void dfs(Node node){
// 遇到叶子节点,递归终止
if(node.left==null&&node.right==null) return;
// 如果存在左子节点,dfs至左子节点
if(node.left!=null) dfs(node.left);
// 如果存在右子节点,dfs至右子节点
if(node.right!=null) dfs(node.right);
}虽然代码中是按照二叉树模板来写的,不过换成矩阵也大同小异,抛开递归终止条件先不提,变化的地方实际上只有子节点的数量而已,二叉树问题我们只是dfs递归了左右2个子节点,而本题不过是增加到4个而已,甚至说即使有1亿个子节点,我们都不畏惧,没有一个循环解决不了的事情。那么本题的难点在哪里呢?答案是回路!回路的定义很简单,即一条dfs路线上出现了圈,比如下图,我们随便在矩阵上画一条线路:
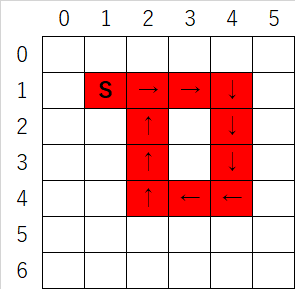
上图中S为DFS路径起点,红色格子代表了该路线,而箭头是该路线的行进方向。我们看到,最终路线的终点与自身的路径相交,这时就产生了回路。回路(交点)的产生,会导致我们的DFS路线无休止的循环下去,因此我们在这类问题中必须要考虑的一件事情即是如何处理回路。这也是DFS解题中经常遇到的问题。解决这个问题的常规做法是使用访问数组,访问数组通常是boolean型:
boolean[][] visited = new boolean[][];
其中visited[row][col],代表第row行第col列这个点是否已经访问过。当遇到已经访问过的点时,我们是没有必要再次访问的,因为该点在之前上层的dfs时(当前路线更早经过改点时)已经处理过,再次处理该点属于重复计算,因此当前dfs路线可以停止。换句话说,当遇到已经访问过的点时,是dfs递归的一个终止条件。我们将目前为止的叙述用代码来描述一下:
void dfs(int row, int col){
// 遇到访问过的点,递归终止
if(visited[row][col]) return;
// 将当前点设置为已访问
visited[row][col]=true;
if(row+1<matrix.length){ // 如果下方没越界
dfs(row+1, col); // 向下移动一格
}
if(row-1>=0){ // 如果上方没越界
dfs(row-1, col); // 向上移动一格
}
if(col+1<matrix[0].length){ // 如果右方没越界
dfs(row, col+1); // 向右移动一格
}
if(col-1>=0){ // 如果左方没越界
dfs(row, col-1); // 向左移动一格
}
}上面的代码很容易理解,它与二叉树的写法大同小异,只是分叉的路线变成了4条,并且递归终止条件变成了已访问过的节点。为了复习上面的内容,这里给大家出两道小问题,可以自行思考一下:
小测验1:如果每一点的前进方向可以是上下左右,左上,左下,右上,右下八个方向时,你应该如何改进上述代码?
小测验2:如果每一点的前进方向是其所在行的下一行的所有点,你应该如何改进上述代码?
我们更进一步来思考一下dfs,对于本题,每一个点都会最多分叉出4条路径,因此,无论从任何一点出发,我们都可以dfs遍历到矩阵上的每一个点。另外,也会存在一条路径就能覆盖整个矩阵上所有点的情况,并且这种路径不仅仅存在一条。
难点还没有结束,我们接着向下分析。对于同一起点出发的不同路线,不论他们的长度或是终点是否相同,我们都认为他们不是同一条dfs路径(除非起点终点以及中间点都相同)。比如:
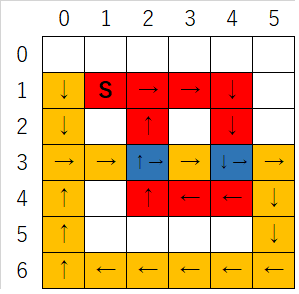
上图中红色路径以及黄色路径均是从S出发,蓝色区域代表了两条路径的相交点。虽然起点相同,但这两条路径明显不是同一路径。这时问题来了,我们在dfs红色路径时,已经将当前路径上的点都标记为已访问状态,那么当dfs黄色路径时,遇到红色路径已访问状态的点(蓝色节点)时是否应该结束递归呢?答案显然是不应该,如果结束的话,黄色路径就不能走到更远的目的地,但是当遇到黄色路线自身已访问过的节点(节点3,0)时,显然又必须结束递归。对于这个问题该如何解决?这就是我们接下来要讨论的话题,访问数组中访问状态的还原。
简单来说,访问数组存在的目的在于避免回路的出现,回路是针对某一条路径来说的,对于多条不同路径相交时,这并不能称之为回路。换句话说,访问数组中的已访问状态只对当前路径有效,在当前路径dfs结束之后,我们应该清除该路径上所有点的已访问状态,以便于不影响其他路径。清除当前路径上所有点的已访问状态,听起来是很复杂的操作,这在代码上该如何写?其实很简单,我们先看实现代码,代码依然在上面的模板基础上做出修改:
void dfs(int row, int col){
// 遇到访问过的点,递归终止
if(visited[row][col]) return;
// 将当前点设置为已访问
visited[row][col]=true;
if(row+1<matrix.length){ // 如果下方没越界
dfs(row+1, col); // 向下移动一格
}
if(row-1>=0){ // 如果上方没越界
dfs(row-1, col); // 向上移动一格
}
if(col+1<matrix[0].length){ // 如果右方没越界
dfs(row, col+1); // 向右移动一格
}
if(col-1>=0){ // 如果左方没越界
dfs(row, col-1); // 向左移动一格
}
// 还原当前点的访问状态,设置为未访问
visited[row][col]=false; // 添加这一行即可
}上面的代码只在最后加了一行就解决了上面的问题。这里我们思考一下,为什么在这里添加这一行代码。首先代码走到最后一行时,意味着当前点向四个方向的分叉dfs递归都已经跑完,也就是说从当前点分叉出的所有路径都遍历结束,这时,当前递归结束,接下来会返回上层递归,上层dfs递归中任何其他三个方向分叉出的路径再次经过当前点时,都不在属于当前路径,也就是与当前路径不是同一条路径,这时,为了不影响其他路径的前进,我们需要在此时将访问状态还原。再换句话说,我们判断回路,可以理解为从经过某一点出发的路径再次回到该点的时刻,而未经过当前点出发的其他路径经过当前点时是不会发生回路的。因此,当从当前点之前出发的其他路径经过当前点时,我们不能影响到其他路径的前进,进而在该处应该清除访问状态。
对于这部分逻辑你可能会感觉很难理解,这需要你慢慢消化,我只能尽可能用我所理解的范畴为你作出解释,这需要大量做题来实践才能慢慢掌握。不过以上写法都是模板套路,即使你还不能完全掌握精髓,至少你要会学照猫画虎。
讲了这么多,我们该回到题目本身了。题目要求找最长递增路径的长度,那么我们需要考虑如下几点:
- 由于起点不确定,因此我们需要以每一个点为起点做dfs路径搜索。
- dfs递归时,我们向4个方向前进时,要判断下一个点的值是否要大于当前点,只有符合条件的方向才能继续向下dfs。
- 记忆数组。
对于前两个问题应该不难解决,而第三个问题你是否想到了答案呢?看到记忆数组几个字你想到了什么?还记得我们在之前文章讲过的动态规划算法吗?
如果你还没看过之前的算法讲解也不要紧,我们在这里再次啰嗦几句。记忆数组的存在是为了减少不必要的重复计算,也许你还没意识到dfs中大量重复计算的存在。我们举例来说明。比如本题,我们通过某一条dfs路径得知了从节点X出发能够得到的最长递增路径,那么当我们再次从另外起点走到X点时,我们就没必要继续dfs下去,直接使用之前计算得出的结果返回即可,这样可以大幅减少递归次数,来达到提高代码效率的作用。如果你对记忆数组还是不能理解,强烈建议去看下上面链接中的文章。
分析到这里,如果你已经完全理解了上文的精髓,我想本题的解法你也大致有了思路。并且对于其他dfs题目,你也应该有自信去尝试解题。本文开头我们已经说过,本篇文章的初衷并非仅仅教会大家本题的解法,而是想让大家明白dfs的核心使用方法,从而到达触类旁通的目的,因此,关于本题的详细实现代码本文就不再阐述,可以作为习题让大家作为练习。如果你还不能写出代码,可以参考我对本题的详细分析:
LEETCODE 329. Longest Increasing Path in a Matrix 解题思路分析
总结:
我们使用了2篇文章的两个例子来介绍DFS算法在解题时的应用,无论是dfs二叉树还是二维数组,其原理的核心都是递归,不同之处在于二维数组在dfs时会出现回路,并且会出现重复计算问题。今后在做题或者面试时,如果我们想使用dfs递归思路来解题,应下意识的要考虑到题目中是否存在重复计算,当存在时千万不要忘记使用记忆数组来保存已经计算过的解。
最后我想我有必要再次解释一下,二叉树那道题目不需要使用记忆数组的原因。我们知道二叉树在分叉之后的所有路线是不会再次相交的,不出现相交也就是说不会再次出现同一个点的重复遍历,这也就是意味着任何分叉出来的路径上的每一点都是还没有遇到过的节点,这也就不存在重复计算的问题。而反观矩阵,分叉出的路径大概率会与其他路径再次相交,相交点之后的所有路径其实是完全相同的,这时我们就没有必要再次做重复劳动了。
最后的最后,我想再说句题外话,我在动态规划算法的讲解中提到过,所有DP题目都可以使用递归加记忆数组来解决,而DFS恰巧就是递归加记忆数组,因此,在我理解来看,DP与某些DFS实际上可以理解为同一类题型(二叉树这种不用记忆数组的除外)。在你刷了足够多的的题目之后,你会发现很多算法实际上是相通的,天下武功,唯快不破,而天下算法,为懂则不难,祝大家刷题愉快,面试成功!
链接:本博客介绍过的所有dfs题目 https://leetcode.jp/tag/dfs/
本网站文章均为原创内容,并可随意转载,但请标明本文链接如有任何疑问可在文章底部留言。为了防止恶意评论,本博客现已开启留言审核功能。但是博主会在后台第一时间看到您的留言,并会在第一时间对您的留言进行回复!欢迎交流!
本文链接: https://leetcode.jp/leetcode常见算法之深度优先搜索dfs超详细白话讲解下/
Pingback引用通告: LEETCODE 1361. Validate Binary Tree Nodes 解题思路分析 - LEETCODE从零刷LEETCODE从零刷
Pingback引用通告: LEETCODE刷题心得-你必须掌握的4类必考题型 - LEETCODE从零刷LEETCODE从零刷