版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://yanzhenjie.blog.csdn.net/article/details/93098495
本文主要帮助读者理解 HTTP 的协作原理、HTTP 相关的各层协议,在服务端和客户端的架构设计和一些优化的技巧,本文中主要讲述逻辑思想和协议远离,会使用部分 Java 代码,但会有详细的讲解,非开发应该也读的明白。
个人实现过一款WebServer/WebFrameWork的 HTTP 服务端框架和两款标准的 HTTP 客户端框架,开源在 GitHub 上后获得广泛好评,在开发这几个开源项目时走过许多弯路,本文也是把我走过的弯路做一个记录和分享,如果能帮助到读者就更好了,如果有笔误的地方还请大家留言指正。
一、本文内容
网络参考模型和 HTTP 协议
TCP/IP 和 HTTP 的数据结构
实现 HTTP 服务端和客户端
HTTP 的传输数据的几种方式
HTTP 常见响应码和响应头的组合使用
读完本文后可以了解到的知识:
TCP/IP 协议、HTTP 协议和 Socket 有什么区别?
如何基于 TCP/IP 实现一个 HTTP 服务端或者客户端?
服务端 HTTP API 发生未处理异常时为什么不会崩溃?
HTTP 在哪些情况下会请求超时?
Cookie 和 Session 有什么区别和联系?
5 个问题基本上贯穿全文。
二、网络参考模型和 HTTP 协议
HTTP 是超文本传送协议(HyperText Transfer Protocol)的缩写,要想具象的描述清楚 HTTP,我们需要先了解OSI 参考模型和TCP/IP 参考模型。
如果有人要我们介绍一下 HTTP 是什么,我相信大多数人会这样回答:
HTTP 是基于 TCP/IP 协议的一个应用层协议。
然而我们真的了解 TCP/IP 协议么?接下来我们一层层抽丝剥茧。
OSI 参考模型
个人认为 TCP/IP 相当于开放式系统互联通信参考模型中的的传输层和网络层,根据该模型的英文单词缩写,它被简称为OSI 参考模型,OSI 参考模型是一个尝试让全世界计算机互联为网络的概念性框架,它只是一个参考模型,并没有提供某种具体的实现方法或者标准,换句话说它是一个为定制标准提供参考的概念性框架。
OSI 参考模型中将计算机网络体系结构划分为 7 层,从下至上依次是:
物理层
光纤和网卡等,负责通信设备和网络媒体之间的互通
数据链路层
以太网,用来加强物理层功能
网络层
IP 协议和 ICMP 协议等,负责数据的路由的选择与数据转寄
传输层
TCP 协议和 UDP 协议等,承上启下,控制连接,控制流量
会话层
建立和维护会话关系
表达层
把数据转换为接受者系统可兼容的格式
应用层
HTTP、FTP、SMTP 和 SSH 等,粗犷的理解为程序员层
OSI 参考模型定义了开放系统的层次结构和各层次之间的相互关系,它作为一个框架来协调和组织各层所提供的服务,如果要说的更贴近一点,它更像是一款行为规范,贴近生活的例子就是一个企业的企业文化。
TCP/IP 参考模型
TCP/IP 协议代表一整个网络传输协议家族,而不仅仅是 TCP 协议和 IP 协议,TCP 协议和 IP 协议是该协议家族中最早通过的最核心的两个协议标准,因此该协议家族被称作TCP/IP 协议族,也就是我们通常所说的 TCP/IP 协议。
要完成一个任务需要该协议家族的各种协议分工协作,就好比程序员分为前端、后端和 DB 等一样,把这些协议根据它们的责任分类,因此 TCP/IP 产考模型应运而生,在该参考模型中的网络体系结构一共分为 4 层,从下至上依次是:
网络连接层
主机与网络相连的协议,如:以太网
网络互联层
IP 协议和 ICMP 协议等,负责数据的路由的选择与数据转寄
传输层
TCP 协议和 UDP 协议等,控制端对端的连接、流量和稳定性
应用层
HTTP、FTP、SMTP 和 SSH 等,粗犷的理解为程序员层
TCP/IP 参考模型看起来和 OSI 参考模型有有一定的相似性,然而由于各种应用层实现的不同,它们之间没有一种绝对的对称关系,我们可以大致的将它们按照以下对应关系来理解和区分:
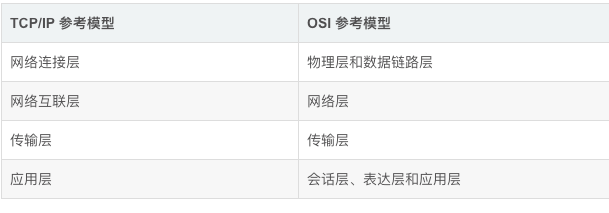
然而上述对应关系依旧有点生拉硬拽的感觉,我认为还是要把它们区分开来理解,从微观上来看它们本身是两种不同的参考模型。
HTTP 协议与 TCP/IP 协议
如果认真的看了上面的表格,我们可以知道,HTTP 是 TCP/IP 参考模型中应用层的其中一种实现。HTTP 协议的网络层基于 IP 协议,传输层基于 TCP 协议,因此就引出了我们开头说到的:
HTTP 协议是基于 TCP/IP 协议的应用层协议。
上文中提到,可以把应用层理解为“程序员层”,TCP/IP 协议需要向程序员提供可编程的 API,该 API 就是 Socket,它是对 TCP/IP 协议的一个重要的实现,几乎所有的计算机系统都提供了对 TCP/IP 协议族的 Socket 实现。
综上所述,我们就可以使用 Socket 来进行网络通信了,而 HTTP 协议也需要向程序员提供可编程的 API,该 API 的实现也就基于 Socket 来实现了。
如何理解 Socket 呢?就像在生活中打电话一样,有打电话的一端,就有接电话的一端,Socket 也是一样的,作为 TCP/IP 协议族的的实现,生来就是为了完成通信。虽然每一台主机设备都可以作为打电话的一端(客户端),也可以作为接电话的一端(服务端),但是打电话和接电话的动作在行为上来看是不同的。
因此计算机系统的 Socket 实现也提供了两套 API,我们在这里约定一下,提供服务端能力的称作ServerSocket,提供客户端能力的称作Socket。
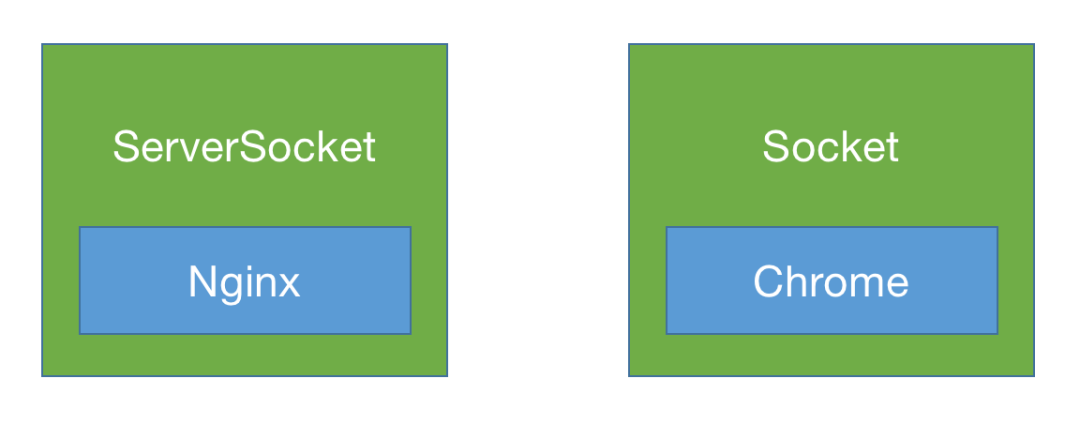
Nginx 和本人开发的 AndServer 等都是基于 Socket 实现的 HTTP 服务端,OkHttp、URLCollection 等都是基于 Socket 实现的 HTTP 客户端,而浏览器就是这些 HTTP 客户端的具象。
到这里,我们就可以回答第一个问题了:
TCP/IP 协议、HTTP 协议和 Socket 有什么区别?
我们先来看几张图,从纵向来看,它们的继承关系是这样的:
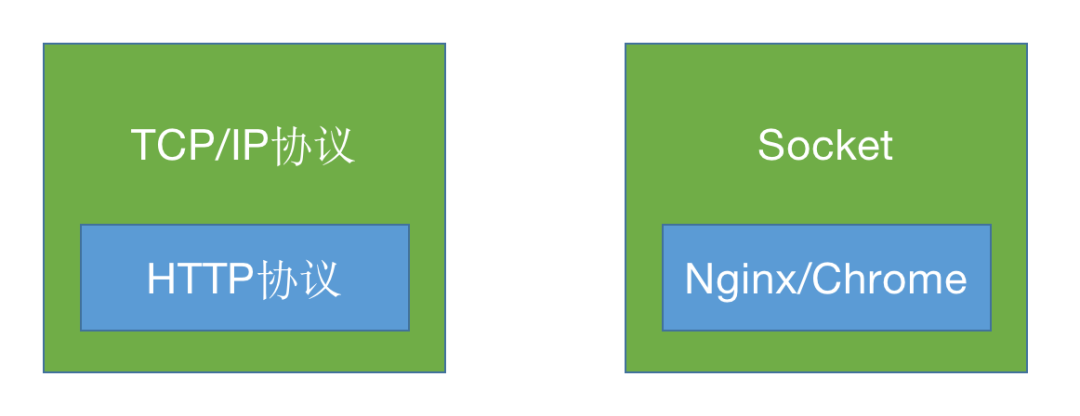
从横向来看,它们的继承关系是这样的:

总结一下,TCP/IP 是一个协议族,Socket 是对 TCP/IP 协议族 API 实现;HTTP 是超文本传输协议的简称,属于 TCP/IP 参考模型的应用层,HTTP 的 API 实现一般都要依靠 TCP/IP 的 API 实现。也就是说一般情况下, HTTP 服务端或者客户端都是基于 Socket 来实现的,而像 Nginx、Apache、Chrome 和 IE 等软件都是基于 HTTP 服务端或者客户端而开发来的。
三、TCP/IP 和 HTTP 的数据结构
HTTP 作为 TCP/IP 参考模型的应用层,谈到它的数据结构势必要了解 TCP/IP 参考模型中其他层的数据结构,把 HTTP 放到 TCP/IP 参考模型中,它们的继承结构是这样的:
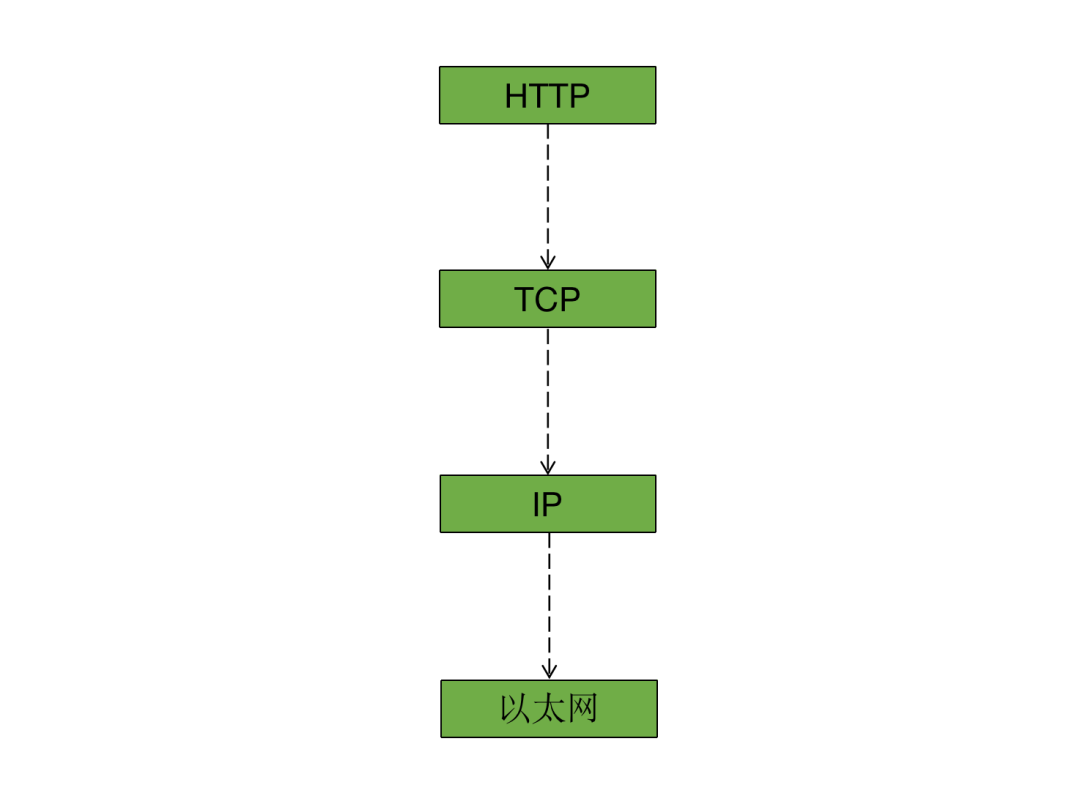
在上述继承结构中,每一层都有各自的结构,就好比爷爷、爸爸和儿子虽然是父子孙关系,但是爷爷有爷爷特点,爸爸有爸爸的特点,儿子有儿子的特点。同样的,上述每一层的结构大致是相同的,基本都是Header + Body这样的结构,以太网还多一层尾部,所以以太网层的结构式是Header + Body + Footer。
如果我们以以太网作为最底层,在 TCP/IP 参考模型中它们的整体的数据结构是:IP 作为以太网的直接底层,IP 的头部和数据合起来作为以太网的数据,同样的 TCP/UDP 的头部和数据合起来作为 IP 的数据,HTTP 的头部和数据合起来作为 TCP/UDP 的数据。我用一个更加形象一点的图来帮助读者理解:
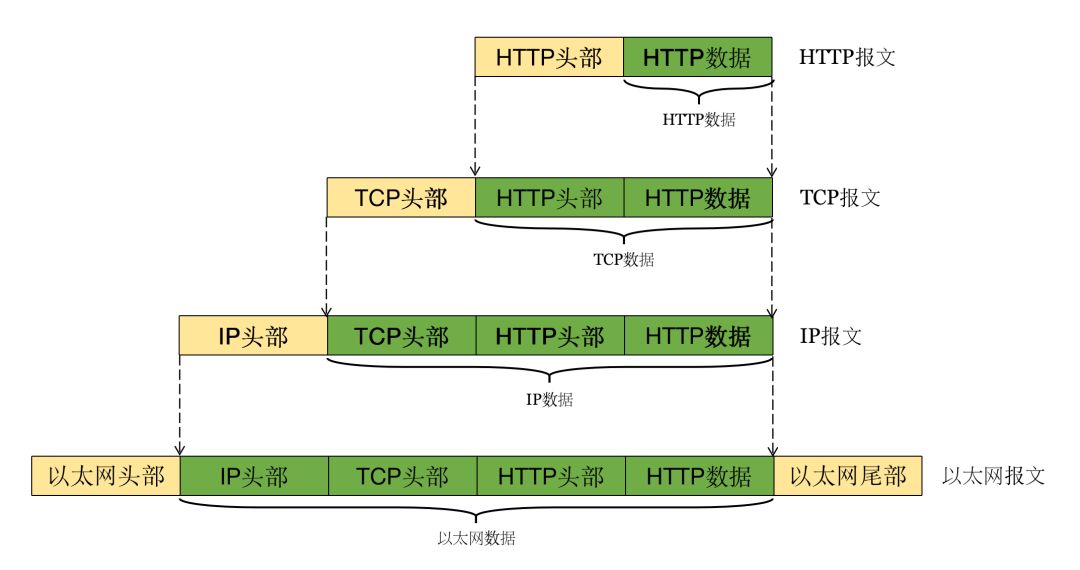
上面这个图还是花了我一点心思和时间的,希望可以切实的帮助到读者。另外要声明的是,在上图中的传输成我使用了 TCP 来代替,实际上还可以使用 UDP 来实现,例如 HTTP3 种就使用了 UDP 作为了传输层。本文中还是依然以 TCP 协议作为传输层讲解。
在 HTTP 中,以太网层的数据结构对于普通开发者来说太底层了,估计讲了也难以理解,我们从普通开发者可以接触到的 IP 层开始讲起。
IP 的数据结构和交互流程
我们都知道在一个成功的 HTTP 请求中,服务端可以在一个请求中获取到客户端 IP 地址,也可以获取到客户端请求的主机的 IP 地址。然而这是怎么做到的呢?
这就有赖于 IP 协议了,在 IP 协议中规定了,IP 的头部必须包含源 IP 地址和目的 IP 地址,这也是为什么在 TCP/IP 参考模型中IP 处在网络互联层,其中一个原因就是可以定位服务端地址和客户端地址,我们来看一下 IP 的数据结构:
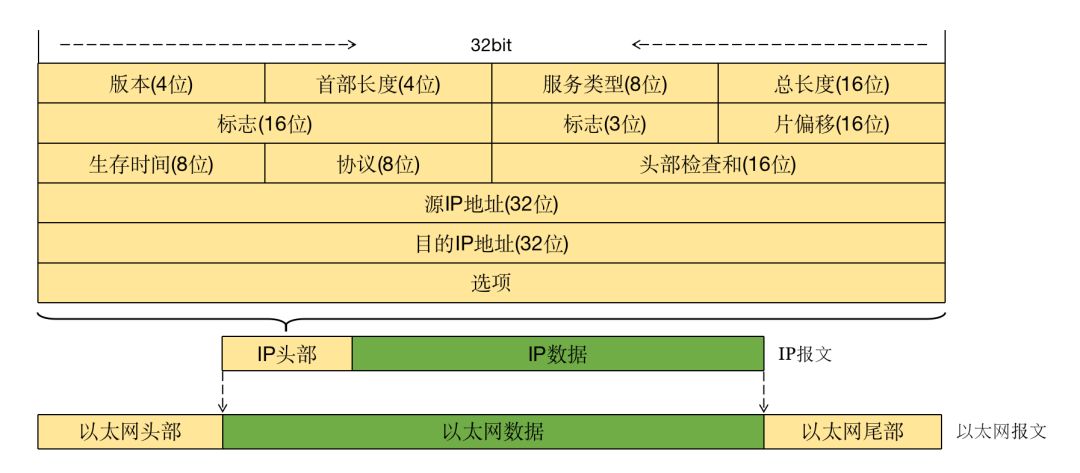
可以很清晰的看到源 IP 地址和目的 IP 地址,在 IP 的头部各占 32 位,而 IPV4 的 IP 地址是用点式十进制表示的,例如:192.168.1.1,在 IP 头部用二进制表示的话,刚好是 4 个字节 32 位。
不过 32 位可以表示的 IP 地址是有限的,目前在全球来看北美拥有 30 多亿个 IP 地址,中国拥有近 3 亿左右个 IP 地址,无奈中国的网民实在太多了,于是使用了 IP 地址转换技术 NAT。
例如 ABC 三个小区的所有设备可能公用了一个公网 IP,通过 NAT 技术分给每一户一个私有 IP 地址,大家在小区内交流时可能使用的是私有 IP 地址,但是向外交流时就用公网 IP。
当客户端要和服务端建立连接时,需要指定服务端的域名或者 IP 地址,在一般情况下,一个主机的 IP 地址是固定且唯一的,在一个主机上也可以部署多个应用。
当客户端使用 IP 地址直链服务端的时候,由于通过地址无法确定客户端要要连接的应用,只能通过指定端口来确定要连接的应用,而要记忆IP + Port对于用户来说非常不友好,所以要通过同一个端口(甚至基于某个应用的默认端口,例如 HTTP 默认使用 80 端口)要连接同一个主机的多个应用只能从地址来下手。
同时由于 IP 地址的特点,让 IP 地址的数量变得有限,并且 IP 地址实际上都被 ISP 所持有,只是租赁给开发者使用,因此当开发者更换了 ISP 时 IP 地址是不会跟着开发者变更的。
基于以上两点就产生了域名,域名是无限多的,如果让多个域名都解析到同一个 IP 地址,那么这么这个主机就拥有了多个别名,当外部应用通过不同的域名来连接该主机时,在该主机内部就可以通过不同的别名,把该连接指向不同的应用。
上面这段话有点绕对吧?我也这么觉得,所以,我来举个栗子:
在你所工作的公司里,有一台服务器,IP 地址是192.168.1.11,在这台服务器上部署了文档网站、设计网站和办公网站,在没有域名的时候分别这样访问这三个网站:
文档网站:http://192.168.1.11:8080
设计网站:http://192.168.1.11:9090
办公网站:http://192.168.1.11:8899
甚至在另一台主机上还部署了 CRM 系统和 CMS 系统等等,这样就要记忆(或者写到小本本上)多个 IP 和不同的端口,现在假设我们公司的域名是666.com,如果我们使用域名的话,上述的地址嫁将会变得很好记忆:
文档网站:http://doc.666.com
设计网站:http://ui.666.com
办公网站:http://oa.666.com
CRM系统:http://crm.666.com
现在,当客户端使用域名连接服务端的时候,需要通过 IP 寻址来确定服务器在网络中的位置,主要是以下两步;
通过 hosts 或者 DNS 查找主机名对应的 IP 地址
通过 ARP 寻址查找主机对应的 MAC 地址
上述两步的主要目的是查到 MAC 地址进行网络连接层的封装和数据发送,MAC 地址是根据 IP 地址进行 ARP 寻址找到的。因此首先得知道指定的域名对应的 IP 地址,此时需要通过 DNS 缓存来查找域名对应的 IP 地址,一般情况下有这么几级:
查找系统的 hosts 中配置的 DNS 映射
查找系统自身的 DNS 缓存
查找路由器中的 DNS 缓存
查找 IPS 的 DNS 缓存
每一级的 DNS 缓存都是有时效性的,在上一层找到对应的映射后就不会向下寻找了。获得了 IP 之后,根据 IP 地址和子网掩码计算出自己所在的网段,在网段内查找对应主机的 MAC 地址,然后在数据链路层进行封装和数据发送。
此处 ARP 寻址讲的比较粗略,因为涉及到了更多的网络协议知识,深入下去之后回脱离 IP,因此点到为止。
TCP 的数据结构和交互流程
我们通常说的 HTTP 的 3 次握手和 4 次挥手都是由 TCP 来完成的,其实这都没 HTTP 什么事,但是有不少人喜欢这么说,严格来说我们应该说 TCP 的 3 次握手 4 次挥手。
要搞清楚 TCP 的交互流程,首先要清楚 TCP 的数据结构,接下来我们来看一下 TCP 的数据结构:
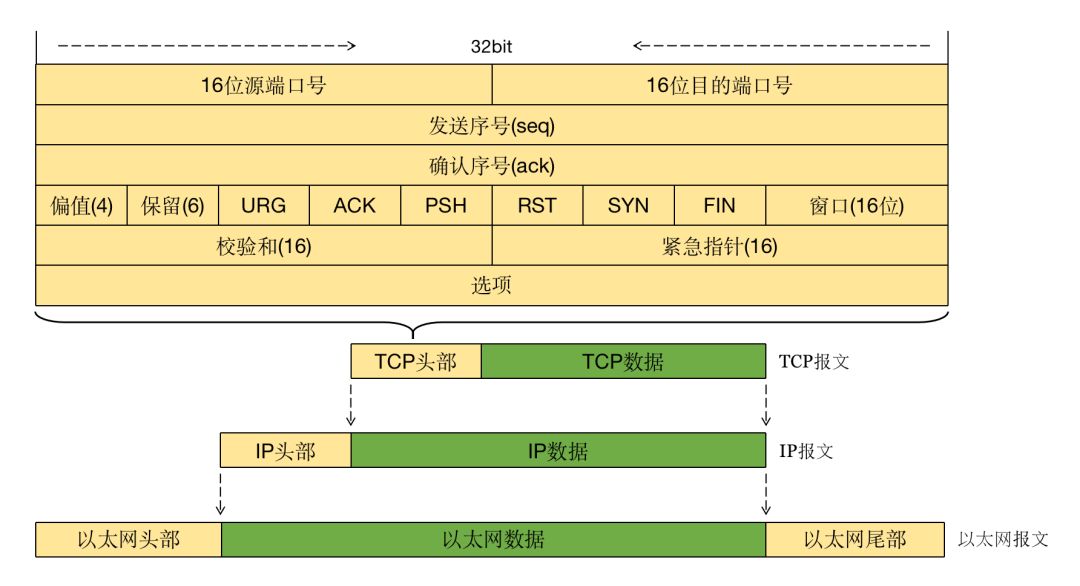
上述 TCP 的数据结构图对于后面理解 HTTP 的交互流程非常重要,我们要记住 5 个关键的位置:
SYN:建立连接标识
ACK:响应标识
FIN:断开连接标识
seq:seq number,发送序号
ack:ack number,响应序号
服务端应用启动后,会在指定端口监听客户端的连接请求,当客户端尝试创建一个到服务端指定端口的 TCP 连接,服务端收到请求后接受数据并处理完业务后,会向客户端作出响应,客户端收到响应后接受响应数据,然后断开连接,一个完整的请求流程就完成了。
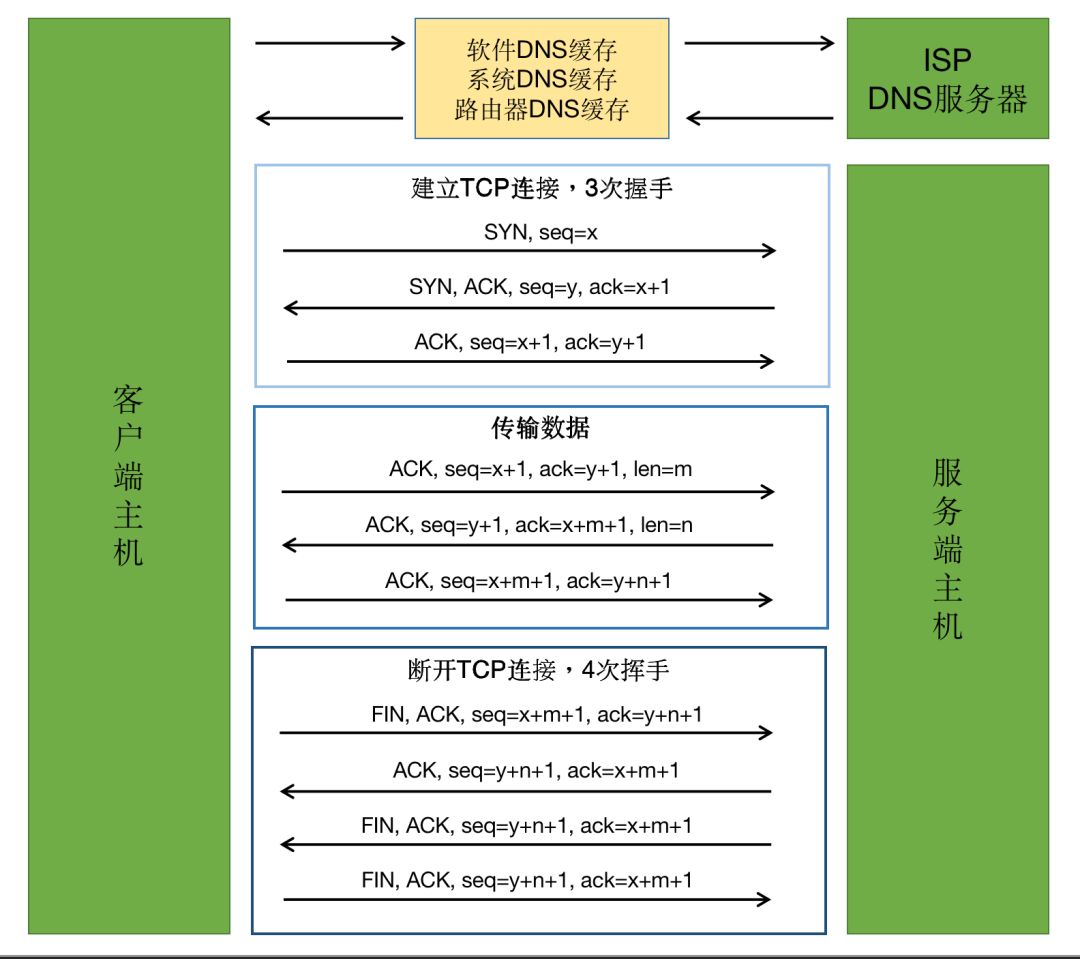
这样的一个完整的 TCP 的生命周期会经历以下 4 个步骤:
建立 TCP 连接,3 次握手
客户端发送SYN, seq=x,进入 SYN_SEND 状态
服务端回应SYN, ACK, seq=y, ack=x+1,进入 SYN_RCVD 状态
客户端回应ACK, seq=x+1, ack=y+1,进入 ESTABLISHED 状态,服务端收到后进入 ESTABLISHED 状态
进行数据传输
客户端发送ACK, seq=x+1, ack=y+1, len=m
服务端回应ACK, seq=y+1, ack=x+m+1, len=n
客户端回应ACK, seq=x+m+1, ack=y+n+1
断开 TCP 连接, 4 次挥手
主机 A 发送FIN, ACK, seq=x+m+1, ack=y+n+1,进入 FNI_WAIT_1 状态
主机 B 回应ACK, seq=y+n+1, ack=x+m+1,进入 CLOSE_WAIT 状态,主机 A 收到后 进入 FIN_WAIT_2 状态
主机 B 发送FIN, ACK, seq=y+n+1, ack=x+m+1,进入 LAST_ACK 状态
主机 A 回应ACk, seq=x+m+1, ack=y+n+1,进入 TIME_WAIT 状态,等待主机 B 可能要求重传 ACK 包,主机 B 收到后关闭连接,进入 CLOSED 状态或者要求主机 A 重传 ACK,客户端在一定的时间内没收到主机 B 重传 ACK 包的要求后,断开连接进入 CLOSED 状态
我把上述流程简化成了一张图片,方便读者理解这个过程:
我们回顾一下 TCP 的数据结构图,可以看到在第四行中,上述提到的 SYN、ACK 和 FIN 都占了一位,也就是说它们的值非 1 即 0,而 seq number 和 ack number 都是 32 位,32 能表示最大的数是 2 的 32 次方减 1:4294967295,目前可预见的未来,在人类的计算机体系中,这个值是完全够用的。
客户端与服务端建立连接、传输数据和断开连接等全靠这几个标识,比如 SYN 也可以被用来作为 DOS 攻击的一个手段,FIN 可以用来扫描服务端指定端口。
HTTP 的数据结构
前面说到了,Socket 是 TCP/IP 的可编程 API,HTTP 的可编程 API 的实现要依赖 Socket。在我看来,HTTP 服务端应用和 HTTP 客户端应用的实现,就是对 Socket 的各种封装和逻辑处理,实际上在我开发 AndServer 和 Kalle 的时候也更加深入的理解了这一点。
因为 HTTP 是超文本传输协议,HTTP 的头和数据看起来更加直观,在大多数情况下,它们都是字符或者字符串,所以对于大多数人来说理解 HTTP 的头和数据格式显得很简单。确实,HTTP 的数据格式理解起来非常容易,上部分是头,下部分是身体。
HTTP 的请求时的数据结构和响应时的数据结构整体上是一样的,但是有一些细微的区别,我们先来看一下 HTTP 请求时的数据结构:
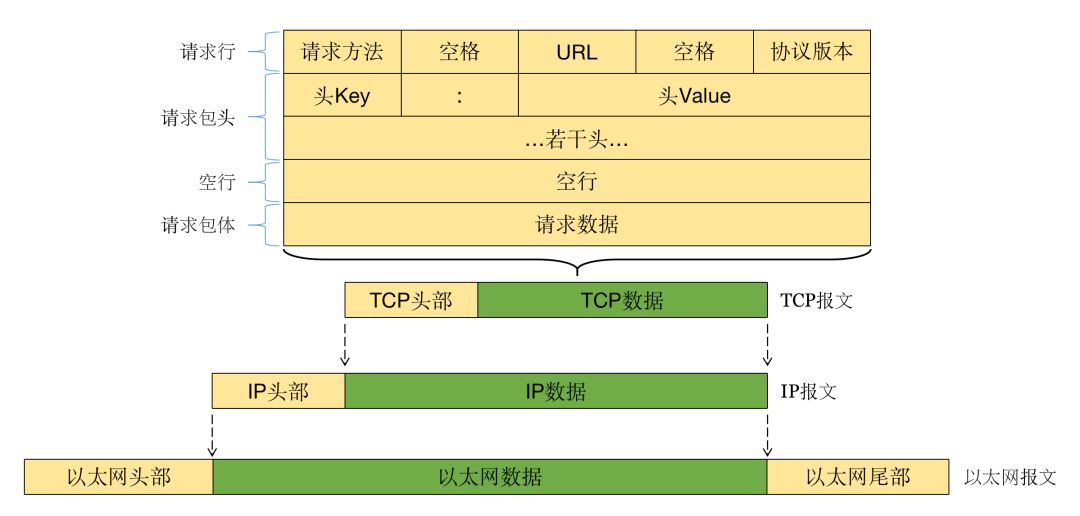
再看一下 HTTP 响应时的数据结构:
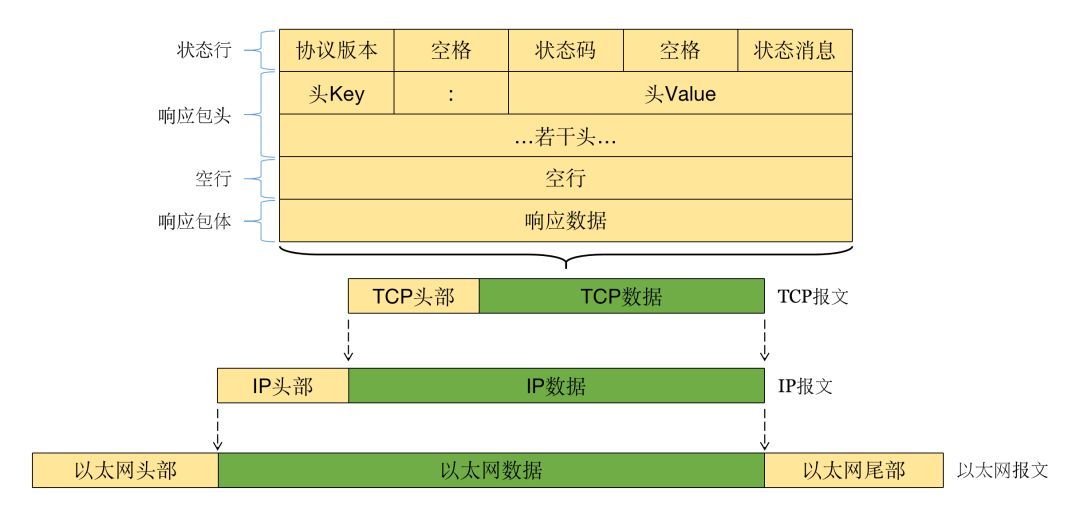
仔细观察从上述图片,我们可以发现它们是有一定格式的文本内容。现在我们使用抓包工具对任意 HTTP 请求抓个包,来对比理解上述结构图,下面是请求某登陆 HTTP API 时的抓包:
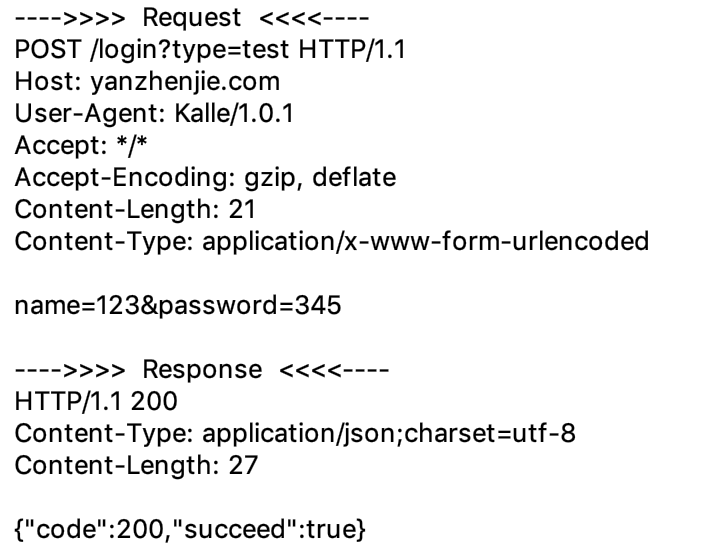
结合上面 3 张图,我们就可以简单的理解 HTTP 的数据结构了。上文中也提到基于 Socket 就可以实现 HTTP 协议的可编程 API,再结合上面两张图,我们可以在脑海里构想一下,如果让我们用 Socket 来实现一个 HTTP 服务端或者 HTTP 客户端,我们可以怎么做?
现在请读者不要往下看,先自己思考一下,如果是让你来实现,你会怎么实现?思考结束后再继续往下看,我会给出例子。
四、实现 HTTP 服务端和客户端
如果读者思考结束了可以向下看了,如果换做是我会这么思考:我们可以使用 Socket 让客户端和服务端建立连接,然后使用 Socket 的输入输出流按照上图的数据结构读写数据,无论实现 HTTP 服务端还是客户端都是这个思路。
这里主要讲解代码思路,有看不懂的同学可以在我 GitHub 上 clone 完整的源代码:
https://github.com/yanzhenjie/HttpImpl
实现 HTTP 服务端
第一步,启动服务端,监听本机 IP 和指定端口的客户端连接:
ServerSocket server = new ServerSocket();
// 要监听的IP和端口
SocketAddress address = new InetSocketAddress("192.168.1.111", 8888)
server.bind(address);
while (true) {
Socket socket = server.accept();
... // 读取请求,发送响应
}
上述代码,从上至下依次指定了监听的 IP 和端口,接着调用ServerSocket#bind()绑定到服务端的 Socket 上,那么这里的端口被占用或者抛出任何一场,代码不会继续向下执行。如果绑定成功,那么则循环监听客户端连接,如果没有人连接则会阻塞在ServerSocket#accept()处,如果有人连接到则向下执行,执行完毕后循环回来等待或者接受下一个连接。
第二步,分发客户端请求,因为会有很多客户端来连接服务端,因此若在同一个线程内处理请求,服务端会忙不过来,我们启动一个新线程来处理请求:
public class RequestHandler extends Thread {
private Socket mSocket;
public RequestHandler(Socket mSocket) {
this.mSocket = mSocket;
}
@Override
public void run() {
... // 读取请求,发送响应
}
}
接着对监听客户端连接做个优化:
while (true) {
Socket socket = server.accept();
System.out.println("---->>>> 发现客户端请求 <<<<----");
RequestHandler handler = new RequestHandler(socket);
handler.start();
}
这样我们就可以监听无数个客户端的连接了。
第三步,简单的读取请求并打印请求数据:
/**
* 读取请求。
*/
private void readRequest(Socket socket) throws IOException {
InputStream is = socket.getInputStream();
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] buffer = new byte[2048];
int len;
while ((len = is.read(buffer)) > 0) {
bos.write(buffer, 0, len);
if (len < 2048) break;
}
System.out.println(new String(bos.toByteArray()));
}
第四步,按照格式发送响应头、换行和响应数据:
/**
* 发送响应。
*/
private void sendResponse(Socket socket, byte[] data) throws IOException {
OutputStream os = socket.getOutputStream();
// 发送响应头
PrintStream print = new PrintStream(os);
print.println("HTTP/1.1 200 Beautiful");
print.println("Server: HttpServer/1.0");
print.println("Content-Length: " + data.length);
print.println("Content-Type: text/plain; charset=utf-8");
// 发送响应头和响应数据之间的换行
print.println();
// 发送响应数据
print.write(data);
os.flush();
}
在上文的结构图中看到每一行响应头后面都会有一个换行,在上述代码中我们调用的是println()方法而不是print()方法,带ln的这个方法在大多数语言中都会在末尾额外输入一个换行,因此这里我们不需要自己再去发送换行符。
现在在线程的run()方法里面调用一下这几个封装方法:
public class RequestHandler extends Thread {
private static final Charset UTF8 = Charset.forName("utf-8");
private Socket mSocket;
public RequestHandler(Socket mSocket) {
this.mSocket = mSocket;
}
@Override
public void run() {
readRequest(mSocket);
String data = null;
try {
// 相当于服务端 HTTP API 处理业务,从数据库查数据等
data = "天上掉下个林妹妹";
} catch(Exception e) {
data = "没什么大不了,就是个 HTTP API 异常了,又不会崩溃";
}
sendResponse(mSocket, data.getByte(UTF8));
// 关闭Socket连接
mSocket.close();
}
}
现在我们就完成了一个简单的 HTTP 服务端,现在启动服务端后,我们在浏览器或者任何 HTTP 客户端请求一下:
http://192.168.1.111:8888
例如我们使用 POST 请求发送一段字符串,现在可以看到控制台的打印:
POST / HTTP/1.1
User-Agent: Kalle/1.0.1
Accept: */*
Host: 192.168.1.111:8888
Accept-Encoding: gzip, deflate
Content-Type: text/plain; charset=utf-8
Content-Length: 15
恰同学少年
我们可以发现浏览器收到了数据:
天上掉下个林妹妹
现在我们就可以回答第三个问题了:
服务端 HTTP API 发生未处理异常时为什么不会崩溃?
从上方的例子中可以看到,当有任何一个客户端链接上来时,服务端都会启动一个新线程来处理这个请求,如果不是Server发生 Crash(上述代码就是个 Server),而仅仅是某个 API 处理业务发生了异常,那么Server是对这个 HTTP API 做了异常包裹的,因此服务端不会崩溃,就算没有对该 HTTP API 做异常包裹,也只是当前这个线程崩溃,客户端拿不到响应,发生超时而已。
实现 HTTP 客户端
第一步,使用 Socket 建立和服务端的连接:
// 要连接的主机域名和端口
InetSocketAddress address = new InetSocketAddress("192.168.1.111", 8888);
// 建立连接
Socket socket = new Socket();
socket.setSoTimeout(10 * 1000);
socket.connect(address, 10 * 1000);
上述代码,从上至下依次指定了主机域名、端口、读取数据超时时间和连接超时时间。调用了Socket#connect()方法后如果和服务端建立连接失败,那么这里会抛出异常,代码不会继续向下执行。
第二步,按照格式发送请求头、换行和请求数据
// 发送请求头
PrintStream print = new PrintStream(socket.getOutputStream());
print.println("POST /abc/dev?ab=cdf HTTP/1.1");
print.println("Host: 192.168.1.111:8888");
print.println("User-Agent: HttpClient/1.0");
print.println("Content-Length: 15");
print.println("Accept: *");
// 发送请求头和请求数据之间的换行
print.println();
// 发送请求数据
print.println("恰同学少年");
在上文的结构图中看到每一行请求头后面都会有一个换行,在上述代码中我们调用的是println()方法而不是print()方法,带ln的这个方法在大多数语言中都会在末尾额外输入一个换行,因此这里我们不需要自己再去发送换行符。
第三步,简单的读取响应并打印响应数据:
InputStream is = socket.getInputStream();
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] buffer = new byte[2048];
int len;
while ((len = is.read(buffer)) > 0) {
bos.write(buffer, 0, len);
if (len < 2048) break;
}
String body = new String(bos.toByteArray());
System.out.println(body);
最后记得断开 Socket 连接:
socket.close();
跑完这段代码后,我们发现控制台有如下输出:
HTTP/1.1 200 Beautiful
Server: HttpServer/1.0
Content-Length: 24
Content-Type: text/plain; charset=utf-8
天上掉下个林妹妹
这里可以把请求地址换成www.csdn.net,记得修改请求头Host的值为www.csdn.net,可以看到也可以正确的收到响应。
至此,我相信读者已经基本了解 HTTP 是什么了。然而,这只是皮毛毛,还远远的不够呢,因为我们只是基于 Socket 模拟了 HTTP 请求,而 HTTP 是怎么传递参数的,是怎么传输文件的,参数有几种传递方式等问题,我们还没了解。
到这里,在不经意间我们已经回答了第二个问题:
如何基于 TCP/IP 实现一个 HTTP 服务端或者客户端?
上面已经回答过第三个问题了,接着我们来回答第四个问题:
HTTP 在哪些情况下会请求超时?
HTTP 请求超时发生在客户端,第一种情况是在建立 Socket 连接的时候,从上文中可知,首先要进行 IP 寻址,在解析域名的时候,如果在 DNS 服务器上找不到该主机,此时还不属于超时,应该是HostNameCanntResolver,当找到该主机对应的 IP 时,开始建立连接,此时如果在指定的时间内不能在数据链路层建立连接则会发生连接超时,此时一般是客户端主机和服务端主机所在的网络不通畅。
第二种情况是在传输数据的时候,在建立连接后,客户端先发送请求数据,如果数据发送到一半,网络突然断开,此时数据一直阻塞在数据链路层,则也会发生超时。
当客户端发送完数据,会尝试接受服务端传回的响应数据,此时服务端可能在处理业务,比如读写数据库,此时在连接层的流中是没有数据在传输的,当服务端操作数据库时间太长(如数据库死锁等)未作出响应,客户端等待超过指定的尝试也会发生超时。
五、
HTTP 传输数据的几种方式
HTTP 是超文本数据传输协议,顾名思义,其用途之一是方便开发者传输数据的,那么为什么不直接使用 TCP/IP 的实现 Socket 还要设计一个应用层的协议呢?一个原因就是便捷性,包括数据格式,数据分割、数据传输和缓存策略等等,如果要为每一个应用单独做一套这样的逻辑,那么不如设计一套规范出来。
还是从上面的 HTTP 的数据结构来说起,从图中可以看出,在请求时可以带数据的位置有 3 个,一是 URL,二是请求头,三是包体,在响应时也有三个位置可以带数据,一是状态消息,二是响应头,三是包体。
请求头和响应头一般是对请求或者响应的整体描述,不做任何与数据层面的相关行为;状态消息用来描述服务端本次响应的状态,是 HTTP 层面的逻辑状态。因此请求头、响应头和状态消息都不适合用来做传输数据。
参数写在 URL 中
URL 是对本次请求资源的一个指向,告诉 HTTP 服务端要请求的资源是哪个,URL 里边也包括 Query 和 Fragment,相当于是对这个资源的特征描述。因此客户端请求服务端时 URL 里面可以带一些参数,但是这种参数属于描述类型,服务端只把它当作查询条件,而不是做作客户端的结果。
这是一个完整的 URL 的结构图:

上图中http://www.example.com:8080是用来描述 TCP/IP 需要的信息,schme表示是否使用SSL建立连接,host表示服务端域名或者 IP,port表示连接的服务端端口。
剩下的/aa/bb/cc?name=kalle&age=18#usage用来描述资源,其中path表示本次请求的资源位置,query表示这个资源的特征,fragment是锚点片段,只用来指导浏览器动作,在 HTTP 请求中无效。
参数写在 Body 中
在 HTTP 数据结构一节可得知,包体都是在头下面空一行开始,包体的内容都是字节流,因此包体里面是可以写任何内容的,事实也是如此。
根据 HTTP 协议,更加规范的来看包体的内容类型可以分为三大类,分别是 URL 参数、任意流和表单。
第一种,发送 URL 参数,在 Body 中的数据是这样拼接的:
name=harry&gender=man
此时,请求头Content-Type是:
Content-Type: application/x-www-form-urlencoded
这种方式看起来和 URL 中的 Query 是一样的,但是意义却不同,这里的参数不是条件,而是客户端的结果或者产物,服务端会当作数据来处理,根据业务的不同,可能写入数据库。
第二种,任意流,可以是字节流、字符流或者文件流等。
例一,发送 JSON 等特定格式数据,在 Body 中的数据是这样的:
{ "name": "harry", "gender": "man" }
此时,请求头Content-Type是:
Content-Type: application/json
例二,发送任意字符串数据,在 Body 中数据是这样的:
你怎么这么好看?
此时,请求头Content-Type是:
Content-Type: text/plain
例三,发送已知类型的文件,比如是一张jpeg的图片,此时 Body 中可以想象成这样:
~~~~~~~~~~~~~~~~~~~~~~~~~
此时,请求头Content-Type是对应的文件的MimeType:
Content-Type: application/octet-stream
例四,未知类型的数据或者文件,此时 Body 中可以想象成这样:
~~~~~~~~~~~~~~~~~~~~~~~~~
此时,请求头Content-Type是:
Content-Type: application/octet-stream
第三种,表单数据,因为表单具有一定的格式,所以只要按照格式上传就可以传递复杂的数据,比如可以在表单中全部传递字符串,也可以全部是文件,也可以是文件和字符串的混合,表单实际上可以理解为一个对象键值对,下面是表单的数据结构:

现在我们使用抓包工具对任意 HTTP 表单请求抓个包,来对比理解上述结构图,下面是使用表单请求某登陆 HTTP API 时的抓包:
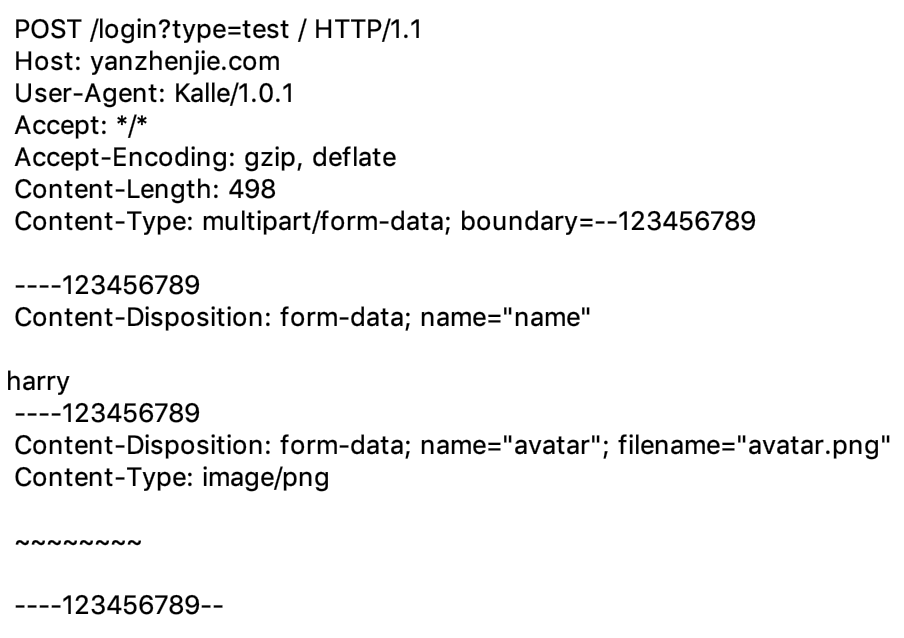
此时,请求头Content-Type是:
Content-Type: multipart/form-data; boundary={boundary}
每一个表单都有一个随机生成的boundary,用来分割表单数据。我们把表单的每一项都成为Part,每一个 Part 都以–boundary开始,接着跟上该Part的描述头信息,接着跟一个换行,然后是该Part的正文数据。按照该规律,依次把所有项都写完即可。
六、
HTTP 常见响应码和响应头的组合使用
HTTP 各种响应码说明:
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status
HTTP 各种头说明:
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers
更多的响应码和头的说明请参考上述链接,举一些比较常见的例子。
200 段的响应码
一般表示请求成功,用的最多的是 200。
其中比较常见且特殊的是 206,一般用于下载文件时的断点续传,假设服务端的一个文件有200 byte,客户端下载到100 byte时中断,下次想从100byte处继续下载,在发起请求时添加请求头Range: bytes=100-,如果服务端支持这个操作,那么返回响应码 206,并且在响应头中添加Content-Range: 100-199/200,此时客户端读到的数据就是第 101 个字节到第 200 个字节。
Content-Range前面的100-199俩数字表示开始字节和结束字节的posiiton,后面的200表示文件的总大小。
Range也可可以指定要下载的一段数据,例如客户端想下载第 101 个字节到第 150 个字节,那么可以指定Range: bytes=100-149,那么服务端会返回Content-Range: 100-149/200,该特性经常用在多线程下载中,在网络有保障的提前下可以极大的提高下载效率。
300 段响应码
一般表示请求重定向,用的较多的是 302,表示重定向到其他 URL 下,客户端可以通过响应头的Location发现新的 URL,并重新发起请求。
比较常见且特殊的是304,当某个 URL 的请求返回Cache-Control: public, max-age={int},Last-Modified: Wed, 21 Oct 2020 07:28:00 GMT时,客户端会缓存本次请求到的数据,在2020年10月21日7点28分前对该 URL 的请求都不会连接到服务端,而是直接读取缓存数据。
在该时间点之后会请求服务端,但是加上请求头If-Modified-Since: Wed, 21 Oct 2020 07:28:00 GMT,服务端会拿该请求头的时间和该 URL 对应的数据的修改时间做对比,如果数据发生了变化了则返回200和新数据,如果发现数据没有变化,则仅仅返回304,客户端此时还应该读取缓存。
不过跟该响应码一起常用的还有ETag和If-Match等相关头,请参考上方的链接,这里不再赘述。
400 段响应
一般表示客户端错误,用的比较多的是400,表示参数错误或者服务端未理解客户端请求。
401表示需要账号密码,或者账号密码错误
403表示权限不足
404表示 URL 指定的资源未找到
405表示客户端指定的请求方法不允许
406表示服务端的内容是客户端不能接受的,一般是服务端指定的Content-Type和客户端指定的Accept不能匹配。
415表示客户端的内容是服务端不能接受的,一般是客户端指定的Content-Type和服务端 API 预定的不符合。
416表示服务端不能支持客户端指定的Range请求头,常用于断点续传。
500 段响应码
一般表示服务端发生错误,用的比较多的是 500,表示服务端发生了未知异常。
其他的常见的头
Accept,一般用在请求头中,表示客户端对服务端内容的期望类型,比如application/json,当服务端生成的内容不是 JSON 时,那么可能收到 406 响应码。
Content-Type,在请求头和响应头中都比较常用,一般表示本次包体的内容类型或者格式,服务端或者客户端应该按照该格式来解析数据。
Connection,表示该请求处理完后是否要关闭连接,在 HTTP1.0 中默认是close,表示要关闭连接,在 HTTP1.1 中默认是keep-alive,表示保持连接。
Content-Length,表示内容的长度,这个值对读取内容非常有用,客户端或者服务端可以根据以最优的方法读取流,可以极大的提高读取 IO 的效率。
Cookie,服务端用来标记客户端,比如用户访问过某页面,那么给他一个标记Set-Cookie: news=true; expires=…; path=…; domain=…,当用户下次请求该页面时,请求头会带上Cookie: news=true,服务端会做一些逻辑处理。
Host,每一个请求中都必须带上该头,表示客户端要请求的服务端的域名和端口,一般 Host 中没有指定端口时,HTTP 应用程序默认使用 80 端口连接服务端。
Referer,当前页面的涞源地址,例如从https://www.google.com页面访问了https://github.com,那么 Referer 的值则是https://www.googlt.com。
谈到 HTTP 头,我们便来回答一下第五个问题:
Cookie 和 Session 有什么区别和联系?
我们首先要明白,Cookie 是服务端对客户端的一个标记,它很明白的写明了这个标记的值,例如上方提到的Set-Cookie: news=true…,后面还带了一些时间和路径参数,在这个时间之前无论浏览器是否重启(连接重建),针对该domain的请求都会的带上该 Cookie。
Session 在 HTTP 中的头或者数据中并没有具体体现,它是服务端 Server 的一个逻辑实现,通过 Cookie 来实现。
事实上,Session 表示会话,当客户端和服务端建立连接后,Server 会为该客户端生成一个 Session,Session 在服务端是一个对象,该对象可以存储很多数据,因为这些数据是用户不能看到的,所以在文件或者数据库中有个 Session 的列表,该文件或者数据库是 Session 的持久化实现,用来防止内存数据丢失。
因此每一个 Session 都会有一个列表中的 ID,为了让该 Session 和当前连接的用户关联起来,把该 Session 的 ID 作为 Cookie 的值发送到客户端,当客户端下次请求服务器时会带上之前的 Cookie 的值,那么服务端拿到这个 Cookie 值后就可以查询到这个 Session,也可以拿到该 Session 中保存的很多值了。
例如,客户端请求服务端登陆的 API 了,现在生成一个 Session:
public void login(Request request, Response response) {
// 获取请求参数中的名称和密码
String name = request.get("name");
String pwd = request.get("pwd");
// 把名称和密码保存一个对象中
Account account = new Account();
account.setName(name);
account.setPwd(pwd);
// 在用户的Session中保存上述名称密码对象
Sesssion session = ...;
session.setObject("user_account", account);
// 在Server上保存Session并生成ID
String sessionId = saveSession(session);
// 把该SessionID加入到Cookie中发送给客户端
Cookie cookie = new Cookie();
cookie.setKey("session_id");
cookie.setValue(sessionId);
response.addCookie(cookie);
...
}
上述是伪代码,帮助读者理解 Cookie 和 Session 的,实际的开发中并不是这么简单的处理。
此时会有一个这样的响应头发送给用户端:
Set-Cookie: session_id=xxxxxx
现在用户在访问获取个人信息的 API 时会带上这样一个请求头:
Cookise: session_id=xxxxxx
此时服务端是这样处理的:
public String ownerInfo(Request request, Response response) {
// 获取key为session_id的Cookie
Cookie cookie = request.getCookie("session_id");
// 获取该Cookie中的值,也就是Session的ID
String sessionId = cookie.getValue();
// 根据SessionID在Server上获取对应的Session
Session session = getSession(sessionId);
// 获取Session中的对象
Account account = session.getObject("user_account");
...
}
以上代码服务端就可以拿到之前为与该用户的会话保存的各种对象了,这个整个流程就是 Cookie 和 Session 的区别。
本来还要讲一下服务端和客户端的业务设计,因为篇幅限制,本文到这里就要结束了。
另外也可以参考我在知乎上的几个回答:
App token 常用处理机制 和 token 失效会带来什么后果?
https://www.zhihu.com/question/62936562/answer/371225253
Post 方法参数写在 body 中和写在 url 中有什么区别?
https://www.zhihu.com/question/64312188/answer/370779721
HTTP 在什么情况下会请求超时?
https://www.zhihu.com/question/21609463/answer/160100810
下次会专门写一篇 HTTP 的业务设计相关文章,告辞!
本文参考了以下链接的内容:
https://zh.wikipedia.org/wiki/OSI 模型
https://zh.wikipedia.org/wiki/TCP/IP 协议族
https://zh.wikipedia.org/wiki/超文本传输协议
https://zh.wikipedia.org/wiki/网络套接字
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers
热文推荐:
2、面试官问我:一个 TCP 连接可以发多少个 HTTP 请求?我竟然回答不上来…
3、程序员疑似出bug被吊打!菲律宾的高薪工作机会了解一下?
4、“一键脱衣”的DeepNude下架后,我在GitHub上找到它涉及的技术
8、腾讯新开源一吊炸天神器—零反射全动态Android插件框架正式开源
喜欢 就关注吧,欢迎投稿!

本网站文章均为原创内容,并可随意转载,但请标明本文链接
如有任何疑问可在文章底部留言。为了防止恶意评论,本博客现已开启留言审核功能。但是博主会在后台第一时间看到您的留言,并会在第一时间对您的留言进行回复!欢迎交流!
本文链接: https://leetcode.jp/服务端与客户端之间的http设计你应该知道的那些事/