题目大意:
搜索推荐系统
给你一个产品数组 products 和一个字符串 searchWord ,products 数组中每个产品都是一个字符串。
请你设计一个推荐系统,在依次输入单词 searchWord 的每一个字母后,推荐 products 数组中前缀与 searchWord 相同的最多三个产品。如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个。
请你以二维列表的形式,返回在输入 searchWord 每个字母后相应的推荐产品的列表。
示例 1:
输入:products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse" 输出:[ ["mobile","moneypot","monitor"], ["mobile","moneypot","monitor"], ["mouse","mousepad"], ["mouse","mousepad"], ["mouse","mousepad"] ] 解释:按字典序排序后的产品列表是 ["mobile","moneypot","monitor","mouse","mousepad"] 输入 m 和 mo,由于所有产品的前缀都相同,所以系统返回字典序最小的三个产品 ["mobile","moneypot","monitor"] 输入 mou, mous 和 mouse 后系统都返回 ["mouse","mousepad"]
示例 2:
输入:products = ["havana"], searchWord = "havana" 输出:[["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
示例 3:
输入:products = ["bags","baggage","banner","box","cloths"], searchWord = "bags" 输出:[["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]
示例 4:
输入:products = ["havana"], searchWord = "tatiana" 输出:[[],[],[],[],[],[],[]]
提示:
- 1 <= products.length <= 1000
- 1 <= Σ products[i].length <= 2 * 10^4
- products[i] 中所有的字符都是小写英文字母。
- 1 <= searchWord.length <= 1000
- searchWord 中所有字符都是小写英文字母。
如果想查看本题目是哪家公司的面试题,请参考以下免费链接: https://leetcode.jp/problemdetail.php?id=1268
解题思路分析:
题目中所说的推荐,其实是以当前输入文字为前缀的字符串列表,搜索前缀字符串的最好方法,我首先想到的就是字典树,并且字典树还能够保证字典顺序排序,可谓一举两得。这里我先简单介绍一下字典树。字典树的数据结构可以将多个字符串用树形结构描画出来。每个节点代表一个字符串中的一个字符,节点中我们需要定义一个数组,代表与当前字符相邻的下一个字符有哪些。大体的结构如下:
Node{
Node[] children = new Node[26];
}其中children[0]到children[25]分别代表字符’a’-‘z’。一般情况下,我们定义一个根节点root代表空字符,然后将一个字符串按照树形方式逐一存入。比如字符串”ab”:
我们首先定义一个根节点,
Node root = new Node();
然后将a存入树中,
root.children[0]=new Node();
然后再将b存入a的下面,
root.children[0].children[1]=new Node();
这样字符串”ab”就已经保存至字典树中,接下来,比如我们还想将ac添加至树中,同理,我们还需要从根节点开始,先看下a是否已经存在于根节点,由于已经存在,我们可以跳过,再看a节点下是否存在c,很显然,目前,a下面只有b,我们需要将c添加至a的下面:
root.children[0].children[2]=new Node();
这样我们就将两个字符串, “ab” 和 “ac” 同时放入了一个字典树中。
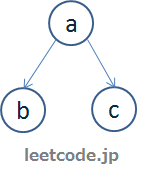
这样,树中的每一条路径都代表这一个单词。再看一个相对复杂的字典树,我们以题目中的示例1为基础来构建一个树,

这个树形结构将5个单词的关系描画的非常清晰,黄色节点代表一个单词的结尾位置,也就是说从顶点到任意一个黄色节点都能够组成一个单词,如果我们想找以”mo”开头的所有单词,直接看 “mo” 节点开始到黄色节点的路径有哪些,就能快速的找出相应的单词列表。另外我们可以从树的左侧开始向右侧遍历,即是按照字典顺序查找。
实现代码:
class Node{ // 字典树节点
Node[] children = new Node[26]; // 该节点后续连接的字符
String fullString; // 如果该节点为字符串结尾,保存该字符串
}
public List<List<String>> suggestedProducts(String[] products, String searchWord) {
Node root = new Node(); // 字典树根节点
for(String p : products){ // 循环每个单词创建字典树
Node r=root; // 当前根节点
// 循环当前单词每个字符,存入字典树
for(int i=0;i<p.length();i++){
// 当前字符的index
int index=p.charAt(i)-'a';
// 如果当前字符不在当前节点的子节点中
if(r.children[index]==null){
// 添加当前字符到子节点
r.children[index]=new Node();
}
// 更新当前根节点
r=r.children[index];
}
// 当前字符串所有字符插入完成之后,
// 将当前节点设置为当前单词结束节点。
r.fullString=p;
}
// 返回结果
List<List<String>> res = new ArrayList<>();
// 循环searchWord的每个字符
for(int i=0;i<searchWord.length();i++){
// 如果当前根节点为空,说明不存在以当前字符开头的单词
if(root==null){
res.add(new ArrayList<>());
continue;
}
// 将根节点更新至当前searchWord的字符所在节点
root=root.children[searchWord.charAt(i)-'a'];
// 取得该节点下存在的单词
res.add(getList(root,new ArrayList<>()));
}
return res;
}
List<String> getList(Node root, List<String> list){
// 如果根节点为空或者已经找到3条数据,返回list
if(root==null || list.size()==3){
return list;
}
// 如果当前节点为单词结尾,将该单词加入返回结果
if(root.fullString!=null){
list.add(root.fullString);
}
// 循环当前节点下所有分支
for(int i=0;i<26;i++){
// 如果当前分支存在字符
if(root.children[i]!=null){
// 递归查找当前分支下完整单词
getList(root.children[i], list);
}
}
return list;
}本题解法执行时间为34ms。
Runtime: 34 ms, faster than 47.69% of Java online submissions for Search Suggestions System.
Memory Usage: 51.3 MB, less than 100.00% of Java online submissions for Search Suggestions System.
本网站文章均为原创内容,并可随意转载,但请标明本文链接如有任何疑问可在文章底部留言。为了防止恶意评论,本博客现已开启留言审核功能。但是博主会在后台第一时间看到您的留言,并会在第一时间对您的留言进行回复!欢迎交流!
本文链接: http://leetcode.jp/leetcode-1268-search-suggestions-system-解题思路分析/
Pingback引用通告: LEETCODE 676. Implement Magic Dictionary 解题思路分析 - 関小君刷题记関小君刷题记
Pingback引用通告: LEETCODE 208. Implement Trie (Prefix Tree) 解题思路分析 - LEETCODE从零刷LEETCODE从零刷