前一篇的算法讲解中我们一起深入了解了深度优先搜索DFS在解题时的应用场景,本篇文章我们将一起探讨一下DFS的亲兄弟BFS算法。
bfs是 breadth first search 的英文缩写,中文名称为广度优先搜索。无论是bfs还是之前讲过的dfs,他们都是快速遍历节点的算法代表,相比于dfs以路径遍历所有节点而言,bfs则是采用逐层遍历的方式,从近到远逐渐覆盖整个区域。还记得我们曾经讲过的dfs的使用场景吗?实际上bfs的使用场景与dfs非常相似,我们一起来看:
- 遍历树结构
- 遍历图结构
- 遍历二维数组
接下来我们使用一道二叉树的例子来做说明。这也是我们讲解dfs时用过的题目。
例:层数最深叶子节点的和
给你一棵二叉树,请你返回层数最深的叶子节点的和。
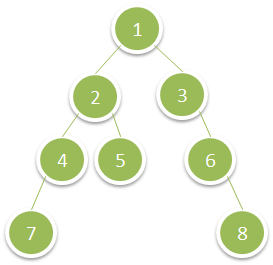
输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8]
输出:15
原题链接:
- 英文: https://leetcode.com/problems/deepest-leaves-sum/
- 中文: https://leetcode-cn.com/problems/deepest-leaves-sum/
- 题目公司信息: https://leetcode.jp/problemdetail.php?id=1302
如果看过我之前文章的话,你应该还记得dfs的解题方法吧!我们先求出最深层的层数,然后再dfs遍历二叉树中所有从根节点出发到每个叶子节点的路径,如果叶子节点的层数是最深层,我们就将其节点的数值累加至返回结果。
对于解二叉树的题目,bfs也是很好的选择之一,我们接下来来看下bfs的核心思想。上文提到过,bfs是以逐层遍历节点的方式来运行的,那么什么是层的概念?我们还是通过上面的二叉树来做个简单的说明,看下图:
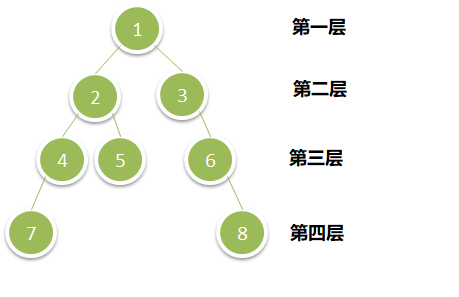
其实层的概念并不难理解,处于同一水平线上的所有点都是同一层的节点,bfs的起点依旧是根节点,我们定义根节点的层数为1(定义为0也可以,看你喜好),那么第一层只有一个根节点1,而第二层有2,3两个节点,同理第三层存在4,5,6这三个节点。最后一层是7和8两个节点。按照层遍历即是从上到下,每次遍历一层中的所有节点,同时记录下该层节点所有的下层子节点,然后再遍历下一层子节点,直到遍历到最后一层为止。这就是bfs的核心遍历逻辑。
如果你觉得bfs的思想很简单,那我们再举个复杂一些的例子,看下图:

上图是一个矩阵,矩阵内存在一个红色区域,请你使用上面讲过的bfs思路,求出红色区域距离矩阵边缘的最短距离。
我们用肉眼很容易看出答案是3,如果使用bfs的话,我们该如何做,矩阵中哪个点是bfs的起点呢?因为是求红色区域距离边缘的最短距离,因此整个红色区域都是bfs的起点,它的下一层是距离红色区域1格的所有点,如下图黄色区域:
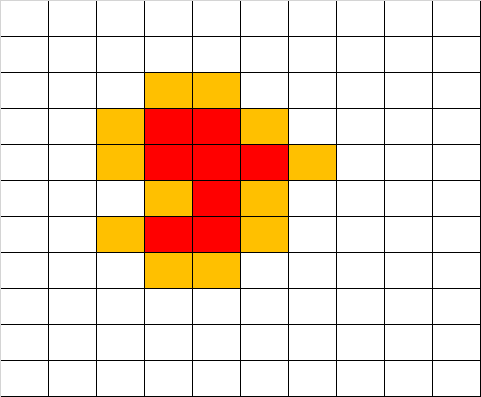
黄色区域即是我们bfs迈出的第一步,如果红色区域被定义为第一层的话,那么黄色区域就是bfs的第二层。接下来,你应该能够想到第三层的样子了吧?看下图蓝色区域:
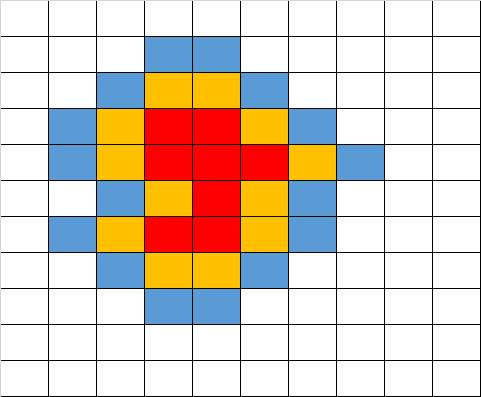
同理,我们再画出第四层,如下图黑色区域:
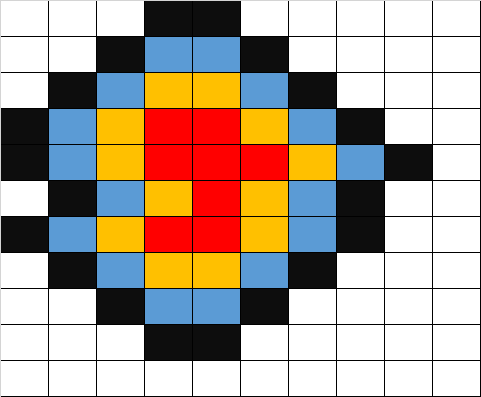
我们发现,bfs到第四层时,已经存在接触到边缘的格子了,也就是说我们通过3次bfs从红色区域到达了矩阵的边缘,因此,红色区域与边缘的最小距离为3。
看到这里,我想你已经对bfs的思想非常了解,接下来该轮到代码出场了!bfs写法实际上已经有了非常规范的模板,我们来详细介绍一下。与dfs的递归方式不同,bfs采用Queue的方式存储每一层的节点,然后在必要的时候还会使用访问数组来记录已经遍历过的节点,避免重复遍历相同区域。
先看下Queue的使用,首先我们需要将bfs起始节点都加入到Queue中,比如二叉树的根节点,或者矩阵中红色区域的所有节点。这一步我们称之为对bfs进行初始化。初始化操作结束后开始进入bfs操作。首先我们需要确定当前Queue中元素个数size,接下来,我们循环size次,每次从Queue中取出一个节点元素,并且将该节点元素的子节点(根据题目也可能是下一个节点,比如矩阵当前位置的相邻元素)添加到Queue中,循环完size次之后,说明我们已经取出了所有初始化操作时添加进Queue的起始节点,当前Queue中剩余的节点元素应该都是起始节点的子节点。到此为止,我们可以记录当下进行了一步bfs操作。接下来,再次取得当前Queue中元素个数size,并且再循环size次,从Queue中取出size个元素,并将它们的子节点加入到Queue,重复上述步骤,直到遇见终止条件(例如到达矩阵边缘)或者Queue的size为0(例如到达二叉树最深层叶子节点,没有更多子节点)为止。
我们将上面的文字用代码来展示一下,代码以二叉树的题目为例:
public int bfs(TreeNode root) {
// 定义bfs用的Queue
Queue<TreeNode> q = new LinkedList<>();
// 初始化bfs,将起始节点根节点加入Queue
q.offer(root);
// 如果Queue不为空,一直循环
while(q.size()>0){
// 取得当前Queue中元素个数
int size=q.size();
// 当前行的元素和
int sum = 0;
// 遍历当前行的所有元素(循环size次)
while(size>0){
// 从Queue中取出一个节点元素
TreeNode n =q.poll();
// 当前行元素个数减一
size--;
// 当前元素的值累加至sum
sum+=n.val;
// 如果左子节点不为空,添加至Queue
if(n.left!=null) q.offer(n.left);
// 如果右子节点不为空,添加至Queue
if(n.right!=null) q.offer(n.right);
}
// 如果Queue为空,说明已到最深层,终止bfs,返回当前层的sum
if(q.size()==0) return sum;
}
return 0;
}上述就是bfs的模板代码,根据不同的题目,你需要对上述模板进行少许修正,再举一个例子,比如我们使用bfs来求解二叉树的最深层层数,代码应该变为:
public int bfs(TreeNode root) {
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int deep=0; // 二叉树层数
while(q.size()>0){
int size=q.size();
// bfs循环当前层
while(size>0){
TreeNode n =q.poll();
size--;
if(n.left!=null) q.offer(n.left);
if(n.right!=null) q.offer(n.right);
} // bfs当前层结束
deep++; // 层数加一
}
return deep;
}接下来我们再看访问数组的使用方法,其实关于访问数组,我们在dfs算法的讲解中已经很详细的介绍过,定义访问数组的目的是为了记录已经遍历过的节点,避免重复遍历,而二叉树问题中不需要设置访问数组的原因在于,二叉树遍历都是向下遍历,不会出现同一节点被遍历到2次的情况。而数组或者图形结构的题目就不同,比如上面矩阵那个例子中,如果我们不使用记忆数组的话,我们就很难保证每次dfs都只向外圈扩散一格。如果大家对访问数组或是dfs算法不太了解,建议你在理解完本篇bfs算法之后,参考一下LEETCODE常见算法之深度优先搜索DFS超详细白话讲解(上)这篇文章。
进阶思考:
本文到此为止,实际上已经大致介绍完bfs的相关知识。不过如果你想对广度优先搜索进行进一步的了解,你需要考虑如下2个问题:
- bfs最擅长解决哪一类问题?
- bfs与dfs的效率哪个更好?
首先,bfs最擅长解决哪一类问题?我们知道,bfs是按照层来遍历节点的,也就是说他会从第一层遍历到第n层,这样一来,如果题目求某个条件下的最短路径时,他就可以最大限度的发挥出优势,比如矩阵那个例子中,最短路径为3,其实我们只需要bfs到第三层就可以得出答案,大于第三层额所有节点我们都无需考虑。如果改用dfs的话,我们不遍历完所有路径,是无法确定哪一条路径最短的。
另外,关于dfs与bfs的效率问题,只能说他们各有千秋,dfs在配合记忆数组的前提下与bfs的解题效率几乎没有差别,如果都是遍历所有节点的前提下,两者的时间复杂度均为O(n),n为总节点数量。而在二叉树遍历上,由于不会使用到记忆数组,虽然两者的时间复杂度相同,但dfs不需要使用到额外的存储空间(Queue),他在执行速度与空间复杂度上都会优于bfs(本题使用bfs解上述二叉树问题只是为了让大家理解广度优先搜索的算法而已)。总而言之,当遇到二叉树,图型题目(某些矩阵题目)的时候,你应该首先想到使用dfs或者bfs,知道了这一点,你就已经战胜大部分竞争者了。对于具体使用哪一种算法,这是你需要自己去体会总结的,最后祝大家刷题愉快!面试顺利。
bfs相关题目讲解: https://leetcode.jp/tag/bfs/
本网站文章均为原创内容,并可随意转载,但请标明本文链接如有任何疑问可在文章底部留言。为了防止恶意评论,本博客现已开启留言审核功能。但是博主会在后台第一时间看到您的留言,并会在第一时间对您的留言进行回复!欢迎交流!
本文链接: http://leetcode.jp/leetcode常见算法之广度优先搜索bfs超详细白话讲解/
Pingback引用通告: LEETCODE 1568. Minimum Number of Days to Disconnect Island 解题思路分析 - 関小君刷题记関小君刷题记
Pingback引用通告: LEETCODE 1553. Minimum Number of Days to Eat N Oranges 解题思路分析 - 関小君刷题记関小君刷题记
Pingback引用通告: LEETCODE 1514. Path with Maximum Probability 解题思路分析 - 関小君刷题记関小君刷题记
Pingback引用通告: LEETCODE刷题心得-你必须掌握的4类必考题型 - LEETCODE从零刷LEETCODE从零刷
Pingback引用通告: LEETCODE 733. Flood Fill 解题思路分析 - LEETCODE从零刷LEETCODE从零刷